在当今数据驱动的互联网时代,业务系统产生的海量日志是洞察用户行为、监控系统健康、驱动智能决策的宝贵资产。实现日志的实时收集与实时计算,已成为提升业务敏捷性与竞争力的关键技术环节。本文将探讨一套结构清晰、易于实施的简单方案,旨在为中小型团队或项目提供切实可行的实践路径。
一、 实时日志收集方案
实时收集是数据流水线的起点,核心目标是低延迟、高可靠地将分散在各服务器、容器或终端上的日志数据汇聚到统一的数据中枢。
- 日志产生与格式化:应用代码应遵循结构化日志规范(如JSON格式)输出日志,包含时间戳、日志级别、服务名、请求ID、关键业务参数等固定字段,这为后续的解析和处理奠定基础。
- 收集代理部署:在每台数据源服务器上,部署轻量级的日志收集代理。Fluentd 或 Filebeat 是两款优秀的选择。它们负责持续监控指定的日志文件或直接接收应用通过TCP/UDP发送的日志流,进行初步的过滤、解析(如将JSON字符串解析为结构化字段)和标签标记。
- 消息队列缓冲:收集代理将处理后的日志事件,以高吞吐、低延迟的方式发送至一个中心化的消息队列进行缓冲。Apache Kafka 或 RabbitMQ 在此环节扮演核心角色。消息队列解耦了数据生产(收集)与消费(计算),能有效应对数据量激增带来的峰值压力,保证数据不丢失,并为多个下游消费者提供支持。
二、 实时计算方案
实时计算负责对持续流入的日志流进行即时处理与分析,快速产出业务价值。
- 流处理引擎消费:实时计算任务由流处理引擎从消息队列(如Kafka)中订阅并消费日志流。Apache Flink 和 Apache Spark Streaming 是当前主流的选择。Flink因其真正的流处理模型、极低的延迟和强大的状态管理,在实时性要求极高的场景中尤为突出。
- 核心计算逻辑:在流处理引擎中,我们可以定义一系列计算任务:
- 实时ETL:对原始日志进行清洗、格式化、丰富(如关联用户画像数据)。
- 实时聚合统计:例如,按时间窗口(每分钟、每5分钟)统计PV/UV、接口调用次数与平均耗时、错误码分布等。
- 实时监控告警:定义规则(如错误日志率在1分钟内超过5%),实时检测并触发告警(对接钉钉、企业微信或短信通道)。
- 实时特征计算:为在线推荐或风控系统实时生成用户的最新行为特征。
- 结果输出与存储:计算产生的结果需要被持久化或推送给下游服务:
- 实时可视化:将聚合指标写入时序数据库(如 InfluxDB、TDengine)或支持快速查询的OLAP数据库(如 ClickHouse),供Grafana等仪表板工具实时展示。
- 实时服务:将处理后的消息或预警事件直接推送到业务服务或消息通知系统。
- 长期存储:将原始的或清洗后的日志批量存入数据湖(如HDFS、S3)或Elasticsearch,供离线深度分析与历史追溯。
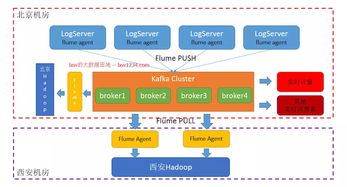
三、 简单架构示例
一个典型的轻量级架构链路可概括为:应用程序 -> (输出结构化日志) -> Filebeat/Fluentd -> (收集转发) -> Kafka -> (缓冲分发) -> Flink Job -> (实时计算) -> ClickHouse/Grafana (展示) & Elasticsearch (检索) & 告警通道。
四、 关键考量与优化点
可靠性:确保消息队列和流处理任务具备高可用性,关键业务数据考虑Exactly-Once语义。
可扩展性:各组件均应支持水平扩展,以应对数据规模的增长。
运维监控:对数据流水线本身(如Kafka堆积、Flink Checkpoint状态)进行监控,保障其稳定运行。
成本与复杂度:对于初创团队,可以从云服务商提供的托管日志服务(如AWS Kinesis、阿里云SLS)起步,以降低运维负担。
构建互联网日志的实时收集与计算能力,并非一蹴而就。从核心的“收集-缓冲-计算-输出”闭环入手,选择成熟、适配的技术组件,并随着业务发展逐步迭代优化,是迈向数据实时化的一条稳健路径。这套方案为快速构建数据驱动的实时业务反馈循环提供了坚实的基础框架。